쿠버네티스 클러스터 모니터링
쿠버네티스의 경우 클러스터 안에 다수의 노드, 그리고 그 안에 파드를 비롯한 다양한 워크로드가 많게는 수백개가 실행되는 형태로 구성되어 있다.
단일 노드의 경우 리눅스 명령어를 이용하여 하드웨어의 상황을 파악하고, 각 프로세스 모니터링을 했다면, 쿠버네티스의 경우 각 노드는 전적으로 컨트롤 플레인에 의해 관리되므로모니터링에 대해 다른 접근 방법을 가져야 한다. 즉, 쿠버네티스 API를 적극 이용해야 한다.
클러스터 환경에서의 문제 해결의 어려움
단일 노드와 비슷하게, 클러스터 모니터링에서도 노드가 사용하는 리소스를 확인할 수 있다. 대표적으로 kubectl top 명령어가 있으며 이 명령어는 노드와 파드가 각각 얼마만큼의 CPU/메모리 리소스를 사용하고 있는지 확인할 수 있습니다.
한편 쿠버네티스 환경에서는, 여러 개의 마이크로서비스가 워크로드로서 실행되고, 또한 클러스터 안에서 서로 연결되어 있는 경우가 대부분일 것입니다. 이 경우 문제의 원인을 찾아내는 것이 조금 더 복잡하다.
예를 들어 백엔드 영역의 파드 하나에서 문제가 발생한 경우, 파드를 연결한 서비스 역시 제대로 작동하지 않을 것이며 사용자는 UI에서 그저 뭔가 문제가 있다는 정도만 확인할 뿐, 실제로 어떤 곳에서 무슨 원인에 의해 발생한지는 알기 어렵다.
이 경우에 각 파드에서 사용하는 리소스에 문제가 발생할 경우 미리 경고를 준다거나, Liveness Probe를 통해 애플리케이션에서 발생하는 응답이 오류로 전달되는 경우 이를 즉시 모니터링할 수 있다면 좋을 것이다.
추가적으로 노드가 물리적으로 멀리 떨어진 상황일 경우 네트워크에 대한 문제가 발생할 수 있다. 따라서 응답 대기 시간(Response Latency)에 대한 점검도 중요하다.
다음은 클러스터 환경에서의 주요 이슈들이다.
- 쿠버네티스 환경 그 자체
- 제어판(컨트롤 플레인)의 주요 컴포넌트 상태가 비정상적인 경우
- 노드의 리소스 가용량 (CPU, 메모리 요청에 대한 비율)
- 노드의 가용한 리소스보다, 리소스 요청량이 커서 파드가 배포되지 않은 경우
- 노드의 리소스 사용량
- 노드 리소스가 부족하여 컨테이너에 크래시가 발생한 경우
- 워크로드 이슈
- 마운트한 파일 시스템의 용량이 부족한 경우
- 특정 컨테이너가 반복적으로 재시작하는 경우
Prometheus 모니터링 시스템
프로메테우스는 오픈소스 모니터링/알림 시스템이다. 프로메테우스는 쿠버네티스, 노드, 프로메테우스 자체를 모니터링 할 수 있다. 쿠버네티스를 지원하고 관리하는 재단인 CNCF에서 프로메테우스 역시 관리하고 있으며, 이 두 도구를 비롯해 시각화를 담당하는 Grafana와 함께 세 도구 조합은 정석적으로 널리 사용되고 있다.
프로메테우스 구성 요소
- 프로메테우스는 시계열(time series) 데이터를 저장합니다.
- 프로메테우스 서버는 다양한 exporter로부터 각 대상의 메트릭을 pull하여 주기적으로 가져오는 모니터링 시스템이다.
- 예를 들어, 쿠버네티스 관련 메트릭을 가져오고 싶다면 쿠버네티스 exporter를, mongoDB 관련 메트릭을 가져오고 싶다면, mongodb exporter를 사용하면 된다.
- Alert manager는 경고 및 알람을 담당한다.
- 사용자가 데이터를 질의할 수 있는 Web UI가 존재한다.
- 이 때 질의 언어로는 PromQL(Prometheus Query Language)을 사용한다.
프로메테우스의 구성 요소는 위 외에도 더 있지만 먼저 알아야 하는 것을 소개했다.
Grafana는 프로메테우스의 구성요소는 아니지만, 프로메테우스에서 권장하는 시각화 도구이.
쿠버네티스 exporter
프로메테우스에서 쿠버네티스 관련 메트릭을 가져올 수 있는 쿠버네티스 exporter가 존재하며 이 때 프로메테우스 exporter는 Kube API를 사용한다. 대부분의 필요한 정보는 가져올 수 있다.
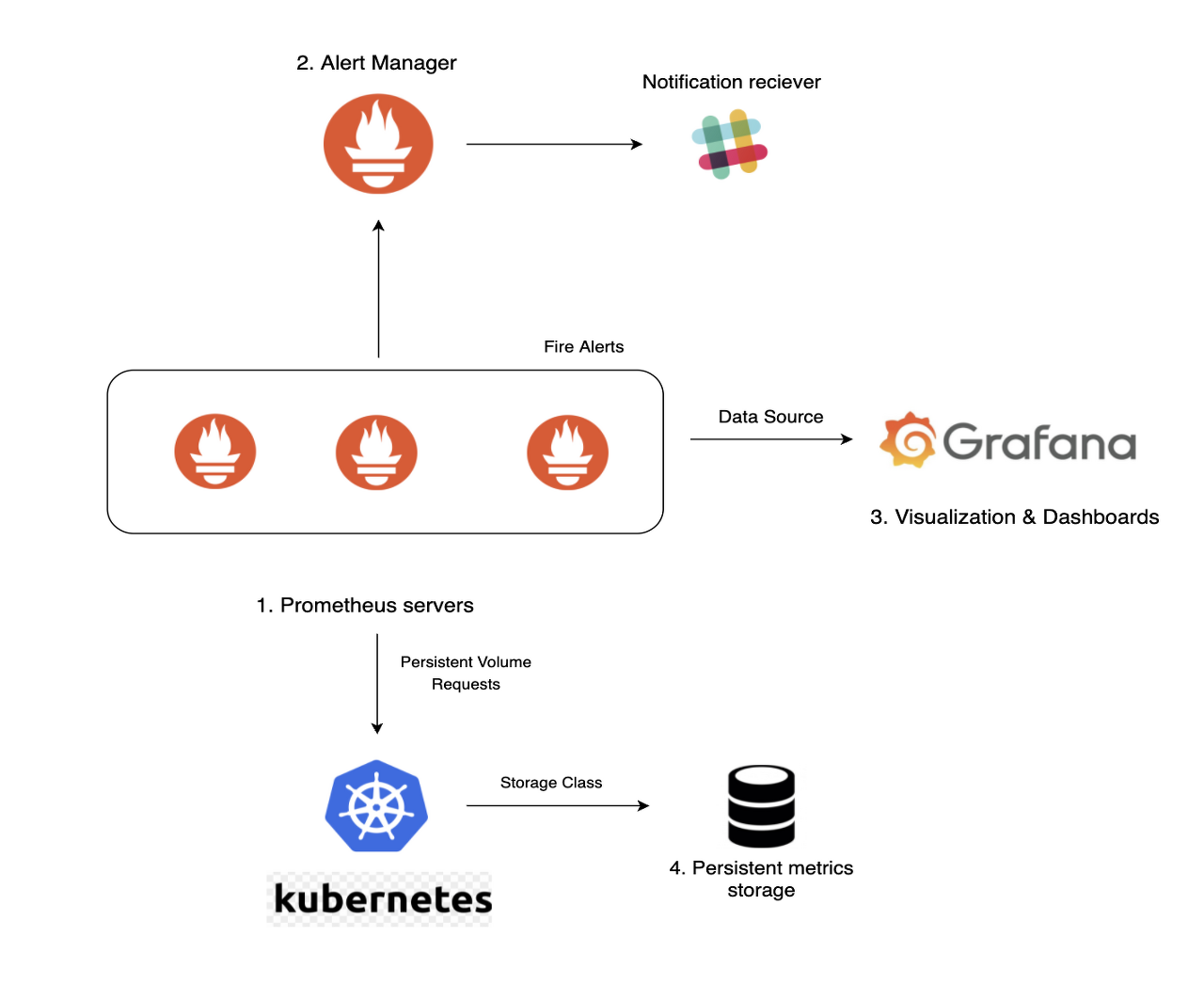
쿠버네티스에서 프로메테우스와 그라파나, 그리고 슬랙과 같은 메신저와의 연동은 보통 다음 그림과 같이 구성한다.
'TIL' 카테고리의 다른 글
| 66일차 서비스 모니터링, 성능 테스트 (0) | 2022.07.19 |
|---|---|
| 65일차 서비스 모니터링 (0) | 2022.07.18 |
| 63일차 서비스 모니터링 (0) | 2022.07.14 |
| 62일차 서비스 모니터링 (0) | 2022.07.13 |
| 57일차 컨테이너 오케스트레이션 (0) | 2022.07.13 |